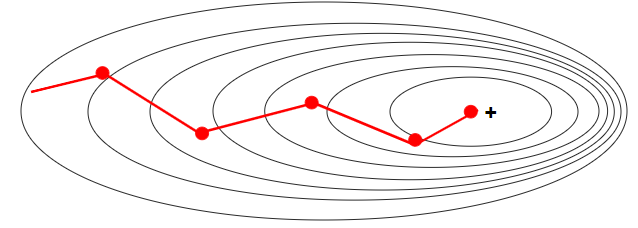
배치 사이즈는 주로 2의 제곱수 배치 사이즈가 작을 때 배치 사이즈를 너무 작게 설정하면 경사 하강법을 통한 가중치 갱신이 불안정하여 최적점에 이르기까지 많은 Iteration을 필요로 한다는 단점 하지만 노이즈가 상대적으로 높기 때문에 지역 최적점(Local Minima)에 빠져나올 확률이 높아진다는 장점 배치 사이즈가 클 때 경사 하강법 과정에서 가중치 갱신이 안정적으로 일어나기 때문에 학습 속도가 빨라짐 배치 사이즈가 1인 확률적 경사 하강법보다 미니 배치 사용한 미니 배치 경사 하강법이 더 빠르게 수렴 큰 배치 사이즈가 좋다고 배치 사이즈를 너무 크게 설정하면 메모리를 초과해버리는 Out-of-Memory 문제 발생 최적의 배치 사이즈 배치 사이즈가 클 때 학습이 안정적으로 잘 되는 것은 사실이지..